Understanding Intrinsic Robustness using Label Uncertainty
Abstract
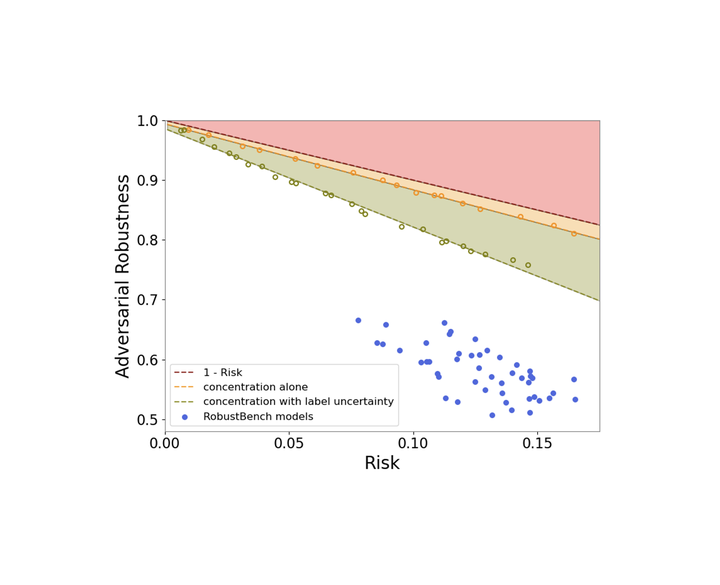
A fundamental question in adversarial machine learning is whether a robust classifier exists for a given task. A line of research has made progress towards this goal by studying concentration of measure, but without considering data labels. We argue that the standard concentration fails to fully characterize the intrinsic robustness of a classification problem, since it ignores data labels which are essential to any classification task. Building on a novel definition of label uncertainty, we empirically demonstrate that error regions induced by state-of-the-art models tend to have much higher label uncertainty than randomly-selected subsets. This observation motivates us to adapt a concentration estimation algorithm that accounts for label uncertainty, resulting in more accurate intrinsic robustness measures for benchmark image classification problems.
A short version of this work was presented at workshop on Security and Safety in Machine Learning Systems at ICLR 2021.